
第二章 开发标准
本章涵盖
- 开发标准简介
- 命名标准
- 编码标准
- 命名规范
- 编码标准
- 风格标准
- 技术标准
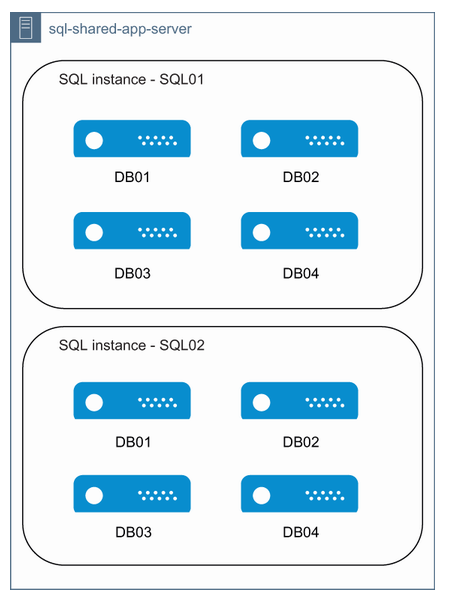
一个错误的服务器和DB命名例子
一个错误的存储过程例子
ALTER PROCEDURE dbo.proc01 AS BEGIN ;with t3 as (select col1, col2, col3 from tbl03) select t1.col1, t2.col2, t1.col2, t1.col3, t3.col1, t3.col2 from dbo.tbl01 t1 inner join tbl02 t2 on t1.col1 = t2.col1 and t1.col3 < 55 inner join t3 on t3.col1 = t1.col1 union select col1, col2, col3, NULL, NULL, '0' from dbo.tbl04 ; END
错误 1: 无描述性的对象名称
一个命名不规范的例子
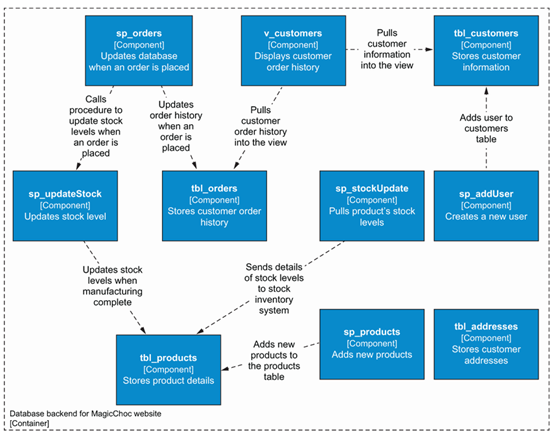
不明晰的参数,一个函数名称
CREATE PROCEDURE sp_orders @CustomerID INT, @LineItems XML, @AddressID INT, @Address INT, @date DATETIME AS BEGIN DECLARE @Stock INT = 0 ; DECLARE @Product INT = 0 ; INSERT INTO tbl_orders ( CustomerID, LineItems, BillingAddressID, DeliveryAddressID, Date ) VALUES ( @CustomerID, @LineItems, @AddressID, @Address, @date ) ; SET @Stock = @LineItems.value(‘(/Product/@qty)[1]’, ‘int’) ; SET @Product = @LineItems.value(‘(/Product/@ProductID)[1]’, ‘int’) ; EXEC sp_stockUpdate @product, @stock ;
修改后的函数例子:更新了参数名字, 使更具意义
CREATE PROCEDURE sp_stockUpdate @ProductStockLevel INT, ① @StockID INT ① AS BEGIN UPDATE tbl_products SET StockQty = StockQty – @productStockLevel WHERE ProductID = @StockID ; UPDATE [DCSVR01\Inventory].InventoryDB.dbo.productStock SET StockQty = StockQty – @productStockLevel WHERE ProductID = @StockID ; END
ALTER PROCEDURE sp_orders @CustomerID INT, @LineItems XML, @BillingAddressID INT, @DeliveryAddressID INT, @OrderDate DATETIME AS BEGIN DECLARE @OrderQty INT = 0 ; DECLARE @ProductID INT = 0 ; INSERT INTO tbl_orders (CustomerID, LineItems, BillingAddressID, DeliveryAddressID, OrderDate) VALUES (@CustomerID, @LineItems, @BillingAddressID, @DeliveryAddressID, @OrderDate) ; SET @OrderQty = @LineItems.value(‘(/Product/@OrderQty)[1]’, ‘int’) ; SET @ProductID = @LineItems.value(‘(/Product/@ProductID)[1]’, ‘int’) ; EXEC sp_updateProductStockLevel @OrderQty, @ProductID ; END
更新后的函数名称
CREATE PROCEDURE sp_updateProductStockLevel @OrderQty INT, ① @ProductID INT ① AS BEGIN UPDATE tbl_products SET StockQty = StockQty – @OrderQty WHERE ProductID = @ProductID ; UPDATE [DCSVR01\Inventory].InventoryDB.dbo.productStock SET StockQty = StockQty – @OrderQty WHERE ProductID = @ProductID ; END
错误2: 使用对象前缀
有些开发人员喜欢使用对象前缀。对象前缀是指在所有表名开头加上 tbl,在存储过程名称开头加上 sp,在函数名称开头加上 fn,在视图名称开头加上 v。想象一下,你有一个包含 250 个表的数据库。你正在寻找某个表的列定义,因此你快速浏览对象资源管理器中的表列表。然而,所有表都有 tbl_ 前缀。这会在浏览时增加理解时间。
错误3: 令人畏惧的 sp_ 前缀
解释为什么 sp_ 前缀值得特别强调的最佳方式是通过一个例子。因此,我希望你考虑 SalesDB 中 sp_AddUser 存储过程的定义,该定义可以在下一个列表中找到。该过程在用户通过 MagicChoc 网站在线注册账户时,简单地将新用户添加到应用程序中。
CREATE PROCEDURE sp_addUser @UserDetails XML ① AS BEGIN OPEN SYMMETRIC KEY MagicChocKey DECRYPTION BY CERTIFICATE MagicChocCertificate ; INSERT INTO dbo.customers ( FirstName , LastName , email , UserPassword ) VALUES ( @UserDetails.value(‘(/User/FirstName)[1]’,’nvarchar(128)’) ② , @UserDetails.value(‘(/User/LastName)[1]’,’nvarchar(128)’) ② , @UserDetails.value(‘(/User/email)[1]’,’nvarchar(512)’) ② , ENCRYPTBYKEY(KEY_GUID(‘MagicChocKey’), @UserDetails.value(‘(/User/ ② UserPassword)[1]’,’nvarchar(128)’)) ③ ) ; CLOSE SYMMETRIC KEY MagicChocKey ; END
DECLARE @UserDetails XML ; ① SET @UserDetails = N’ ② Peter ② Carter ② [email protected] ② myPaSSw0rd ② ‘ ; EXEC sp_adduser @UserDetails ; ③
执行时,会报错:
Msg 257, Level 16, State 3, Procedure sp_adduser, Line 0 [Batch Start Line 94] Implicit conversion from data type xml to nvarchar is not allowed. Use the CONVERT function to run this query.
嗯,这很奇怪!错误显示在存储过程的第 0 行,这意味着在传递 @UserDetails 变量时出现了错误。但并没有发生 NVARCHAR 到 XML 的转换。该变量的数据类型是 XML,而存储过程的参数也定义为 XML 数据类型。
那么到底发生了什么呢?让我们做个实验。我们尝试在不传入任何参数的情况下运行该存储过程,使用语句 EXEC sp_adduser。错误输出是
Msg 201, Level 16, State 4, Procedure sp_adduser, Line 0 [Batch Start Line 104] Procedure or function ‘sp_adduser’ expects parameter ‘@loginame’, which was not supplied.
现在我们遇到了一个不同的错误,但这更奇怪。它抱怨我们没有传递 @loginname 参数。但是我们的存储过程并没有 @loginname 参数。几乎就像我们在执行错误的存储过程一样。我们需要彻底弄清楚这个问题。为此,让我们运行清单 下面的查询,该查询返回来自 sys.all_objects 目录视图的结果。这个对象提供了用户对象和系统对象的并集。
SELECT name , SCHEMA_NAME(schema_id) AS SchemaName ① , type_desc , is_ms_shipped FROM sys.all_objects WHERE name = ‘sp_adduser’ ;
此查询的结果是
name SchemaName type_desc is_ms_shipped
sp_adduser dbo SQL_STORED_PROCEDURE 0
sp_adduser sys SQL_STORED_PROCEDURE 1
结果显示,有两个具有相同名称的存储过程。
第一个结果是我们的存储过程。我们可以通过它位于 dbo 架构中且 is_ms_shipped 标志为 false 来判断。
第二个结果是同名的系统存储过程。我们可以通过它位于 sys 架构中且 is_ms_shipped 标志为 true 来判断它是系统存储过程。
提示:is_ms_shipped 标志表示该对象是由 SQL Server 内部创建的。
系统存储过程存储在一个名为 resource 的“隐藏”只读数据库中,该数据库保存所有系统对象。然而,这些对象似乎出现在所有数据库中,这意味着它们可以很容易地从所有数据库中访问。所有系统存储过程都有 sp_ 前缀,这个前缀应专门用于系统存储过程。
当你执行带有 sp_ 前缀的存储过程时,SQL Server 会首先在 master 数据库中查找该存储过程。只有当在 master 数据库中未找到时,才会尝试在执行该存储过程的本地数据库中查找。
错误4:没有为编码标准腾出时间
想象一下,你在一个由10名开发人员组成的团队中,正在开发一个大型数据层应用程序。你们都是有经验的开发人员,而且有一个紧迫的截止日期需要完成。直接开始写代码可能很诱人。毕竟,你们都已经干过很多类似的项目。你们都知道代码应该用四个空格缩进,对吧?等等!究竟是四个空格还是一个制表符呢?
在两个开发者之间最快引发争论的方式就是讨论编码规范。每个人都有自己遵循的标准,并且每个人都认为自己的标准是最好的。如果我们有一个统一的标准,那么并不是每个人都会同意,但即使它不完美,一致性也意味着它比完全没有标准要好。
根据项目的规模和复杂性,编码标准在其全面性方面可能会有所不同。然而,它们将涵盖风格选择和技术考虑。
与技术标准不同,关于风格标准的一个简单事实是,只要你有标准并在整个项目中一致实施,标准具体内容实际上并不重要。
编码标准就是架构发挥作用的地方。在错误1# 中我们讨论了在 SQL Server 项目中制定架构的必要性,以确保数据库模式得到最佳设计并具有高性能。我们还提到,这种架构应考虑命名规范。架构的另一个方面是确保有一套编码标准供人们遵循。
风格选择可能包括以下元素,例如:
- 代码缩进使用四个空格还是制表符?
- 所有语句是否都应以分号结尾?
- 在列出列名时,逗号分隔符应该放在行末还是下一行的开头?
- ON 子句是否应与 JOIN 子句写在同一行?
- SQL Server 关键字是否都应大写?
- 使用驼峰命名法还是帕斯卡命名法?
技术标准可能包括以下内容:
- 不要使用游标。
- 尽可能使用 UNION ALL 而不是 UNION。
- 不要在 SELECT 列表中使用 *。
- 不要使用 NOLOCK。
- 避免使用 DISTINCT。
错误5:使用序数列位置
SQL Server 支持在 ORDER BY 子句中使用序号列。这意味着,你可以不按照列名排序,而是按照其在 SELECT 子句中的序号位置进行排序。例如,考虑下列清单中的查询。
SELECT * FROM SYS.databases ORDER BY 54 ;
那么我们按哪一列对查询进行了排序呢?答案是 log_reuse_wait_desc 列,但确定这一点的唯一方法是要么数结果集中的列直到第 54 列,要么运行清单 2.16 中的查询,该查询从目录视图中保存的元数据中提取列名。
SELECT c.name FROM SYS.all_columns c INNER JOIN SYS.all_objects o ON o.object_id = c.object_id WHERE o.name = ‘databases’ AND c.column_id = 54 ;
避免使用序号列位置的另一个好理由是,当底层表被修改时,序号列位置并不稳定。例如,如果表中的第二列被删除,那么所有引用第3列及之后列的查询都需要更新,因为序号位置已经发生了变化。
总结:
- 始终使用有意义的对象名称,以便让你的代码具有自我说明性。
- 始终考虑数据库架构,即使在敏捷项目中也是如此。
- 避免为数据库对象使用前缀,因为这实际上可能会使对象更难找到。
- 尤其要小心避免为存储过程使用 sp_ 前缀,因为这表示它们是系统存储过程,而不是用户定义的存储过程。
- 始终抽出时间确保你的数据层应用程序具有编码标准。这些标准应成为你架构工作的一部分,并应考虑样式选择以及技术标准。
- 除非你喜欢排查问题,否则避免按序号列排序!


