
第七章 错误处理、测试、源代码管理和部署
本章涵盖处理
- T-SQL 错误
- 代码故障排除
- 性能测试
- 现代开发实践
当人们想到数据库开发人员的角色时,很容易将注意力完全集中在编写高效的T-SQL代码上。然而,实际上,现代数据库开发人员必须考虑许多其他方面。错误处理是其中的第一个方面。如果一个过程在生产环境中抛出错误,我们希望能够优雅地处理该错误,以降低数据不一致等风险。错误处理甚至可以使代码重试,从而避免应用程序支持团队介入。我们也通常希望在错误发生时收到通知,以便进行调查。
我们还需要能够高效地调试代码错误。代码最终会有漏洞。这是生活的事实。当我们的代码中存在漏洞时,我们需要能够以高效的方式进行调试。如果写一段代码只需一天,但调试它却需要一周,那就毫无意义。因此,在处理复杂代码时,理解调试方法是至关重要的。
我经常看到SQL开发人员犯的一个常见错误是缺乏测试。我们将作为对SQL开发人员现代开发实践(缺乏)采用的更广泛的探讨的一部分来研究单元测试。我们将探讨将代码保存在源代码控制中、编写单元测试以及使用自动化构建和部署管道的好处。在第4章中,我们创建了一个名为MagicChoc的数据库,在第6章中,我们创建了一个名为Marketing的数据库。本章中我们将使用这两个数据库。
现代开发实践要求代码保存在源代码管理中,并使用 DevOps 流程来部署代码。这些实践多年来已经成为常态,但 SQL 开发人员似乎采用得较晚。我见过许多 SQL Server 团队仍将他们的“源代码”存储在数据库备份中,并手动运行复杂、精心制作的脚本来部署他们的数据层应用程序。本章中我们将探讨这两种错误。
开发工具 到目前为止,在本书中,除非我们探讨了 SQL Server 集成服务 (SSIS) 的时候,我一直在使用 SQL Server 管理工作室 (SSMS) 来创建示例,我假设你可能也一直在使用 SSMS 跟随操作。它对 SQL Server 专业人士来说非常熟悉,而且非常容易使用。 我们可以使用其他几种工具来开发 T-SQL,例如 Visual Studio Code、SQL Server 数据工具 (SSDT) 和 Azure Data Studio。对于一些高级开发技术,我们需要使用其中一些额外的开发工具。对于错误
错误26# 编写不处理错误的代码
如果我们的代码在生产环境中失败,最不希望发生的就是出现未处理的错误。如果我们的代码失败,我们希望它能够优雅地失败,并向应用支持团队提供有用的诊断信息,他们需要尝试解决问题。为了探讨这个问题,让我们首先查看一个没有错误处理的存储过程,并看看其中的一些后果。
清单7.1中的存储过程可以在MagicChoc数据库中创建。它是一个简单的存储过程,接受创建新销售订单所需的参数。它根据客户生成SalesOrderNumber所需的前缀,然后将记录插入到SalesOrderHeaders和SalesOrderDetails表中。
CREATE PROCEDURE dbo.InsertSalesOrder @SalesOrderNumber NVARCHAR(12), @SalesOrderDate DATE, @SalesPersonID INT, @SalesAreaID INT, @CustomerID INT, @SalesOrderDeliveryDueDate DATE, @SalesOrderDeliveryActualDate DATE, @CurrierUsedForDelivery NVARCHAR(32), @ProductID INT, @Quantity INT AS BEGIN BEGIN TRANSACTION DECLARE @CustomerPrefix NVARCHAR(12) ; SET @CustomerPrefix = ( SELECT SUBSTRING(CustomerCompanyName,1,3) FROM dbo.Customers WHERE CustomerID = @CustomerID ) ; INSERT INTO dbo.SalesOrderHeaders VALUES ( @CustomerPrefix + @SalesOrderNumber , @SalesOrderDate , @SalesPersonID , @SalesAreaID , @CustomerID , @SalesOrderDeliveryDueDate , @SalesOrderDeliveryActualDate , @CurrierUsedForDelivery ) ; INSERT INTO dbo.SalesOrderDetails ( ProductID , Quantity , SalesOrderNumber ) VALUES ( @ProductID , @Quantity , @CustomerPrefix + @SalesOrderNumber ) ; COMMIT END
让我们通过使用存储过程尝试创建一些销售订单来实践看看。下面清单中的脚本将执行我们的存储过程,销售订单将成功插入到 SalesOrderHeaders 和 SalesOrderDetails 表中。
EXEC dbo.InsertSalesOrder ‘1635D-U06’ , ‘2023-08-19’ , 1 , 1 , 2 , ‘2023-09-01’ , NULL , ‘Get Me There!’ , 5 , 1 ;
到目前为止,一切顺利!该过程运行成功,并且添加了一个销售订单。让我们使用清单7.3中的脚本再次执行存储过程。这一次,在执行存储过程之前,我们将把 SalesOrderDetails 表的名称更改为 SalesOrderLines。自然,这将在事务内部导致失败。
EXEC sp_rename ‘dbo.SalesOrderDetails’, ‘SalesOrderLines’ ; GO EXEC dbo.InsertSalesOrder ‘1637D-U06’ , ‘2023-08-19’ , 1 , 1 , 2 , ‘2023-09-01’ , NULL , ‘Get Me There!’ , 5 , 1 ;
出现了两个错误,如下所示:
消息 208,级别 16,状态 1,过程 dbo.InsertSalesOrder,第 35 行 [批处理起始行 2] 无效的对象名 ‘dbo.SalesOrderDetails’。消息 266,级别 16,状态 2,过程 dbo.InsertSalesOrder,第 35 行 [批处理起始行 2] EXECUTE 后的事务计数显示 BEGIN 和 COMMIT 语句数量不匹配。之前计数 = 0,当前计数 = 1。
正如我们所预料的,第一个错误是由表名不正确引起的。然而,第二个错误更有趣。它指出,在存储过程执行结束时,未完成的事务数量比开始时更多。我们可以通过运行 SELECT @@TRANCOUNT 来测试这一点。假设没有其他未完成的事务,这个值将显示为 1,而理想情况下应该是 0。这是因为事务没有自动回滚。我们需要手动运行 ROLLBACK 命令来清理该事务,如果你正在跟着操作,现在应该执行这个步骤。然后你应该运行以下代码来更正表名:
EXEC sp_rename ‘dbo.SalesOrderLines’, ‘SalesOrderDetails’ ; GO
存储过程内部的代码被包装在事务中,事务是一组一个或多个更新数据的 T-SQL 语句,并作为一个单独的逻辑单元提交或撤销。在最基本的层面上,事务必须具有四个关键属性,这些属性被称为 ACID。ACID 是一个首字母缩略词,代表原子性、一致性、隔离性和持久性。
当我们说一个事务是原子性的,这意味着所有语句要么作为一个整体提交,要么全部撤销(“回滚”)。它们要么全部成功,要么全部失败。当我们说它们是一致的,我们的意思是事务结束时,表中的数据将保持一致状态。为了使事务是隔离的,它不能与同时发生的其他事务进行交互。为了使事务是持久的,提交事务后更新的数据不能丢失,即使 SQL Server 崩溃也不例外。
SQL Server 使用多种机制来确保事务具有 ACID 特性,包括锁定,通过阻止其他事务同时更新其他行来强制隔离,以及通过事务日志进行记录,在事务提交完成之前将日志刷新到磁盘以确保持久性。
然而,需要注意的是,SQL Server 是一个大型、复杂的产品,其中有许多细微差别。例如,可以使用不同的事务隔离级别来改变事务隔离性,我们将在第10章中研究这些内容。
另一种微妙之处是耐久性。一种称为延迟耐久性的功能可以通过减少繁忙系统上的IO争用来提高性能,但代价是耐久性。换句话说,时机不当的系统崩溃可能导致已提交的数据丢失。
关于错误处理,一个非常重要的细微差别涉及原子性和一致性。虽然事务应确保所有数据作为一个单元要么提交,要么回滚,但 XACT_ABORT 的设置将决定这一规则执行的严格程度。如果 XACT_ABORT 设置为 OFF(默认值),那么某些错误,例如数据截断,将不会阻止事务提交其他语句。
让我们看另一个例子。清单 7.4 中的脚本再次执行我们的存储过程。这一次,对象名称是正确的,但我们试图插入一个不存在的 ProductID。这将导致主键冲突。
EXEC dbo.InsertSalesOrder ‘1655D-U06’ , ‘2023-08-19’ , 1 , 1 , 2 , ‘2023-09-01’ , NULL , ‘Get Me There!’ , 86 , 1 ;
此执行的输出是
(影响 1 行) 消息 547,级别 16,状态 0,过程 dbo.InsertSalesOrder,第 35 行 [批处理起始行 0] INSERT 语句与 FOREIGN KEY 约束 “FK__SalesOrde__Produ__619B8048” 冲突。冲突发生在数据库 “MagicChoc”,表 “dbo.Products”,列 ‘ProductID’。
在此输出中,我们可以看到插入 SalesOrderHeaders 表成功,但插入 SalesOrderDetails 表失败。如果此时运行 SELECT @@TRANCOUNT,我们将返回值 0。这意味着事务已经提交。具体来说,它已经提交了第一个语句的插入操作,尽管第二个插入操作失败了。
这是因为如果 XACT_ABORT 被关闭(这是默认行为),那么一些运行时错误,例如死锁或对象名称错误,会导致事务中止,而其他错误,例如键冲突,则会允许事务继续,只使语句失败。
这使我们的数据处于不完整状态。销售订单存在于 SalesOrderHeaders 表中,但没有关联的行项目。此外,该错误的严重性不足以写入错误日志,这将使调试更加困难。
从这些例子中得到的第一个要点是,开启 XACT_ABORT 是一个良好的实践。这可以在存储过程或批处理中通过使用 SET XACT_ABORT ON 来完成。然而,我建议使用以下列表中的脚本为连接到实例的全局连接启用它。
EXEC sp_configure ‘user options’ , ‘16384’ ; GO RECONFIGURE WITH OVERRIDE ; GO
第二个、更重要的收获是,确实有必要在我们的代码中妥善处理错误。SQL Server 提供了全面的错误处理功能,但我看到太多人没有利用它,这是一个错误。
因此,让我们探讨如何编写我们的存储过程,以更好地涵盖错误处理。为此,第一个需要注意的特性是一个名为 TRY..CATCH 的结构,对于有 .NET 背景的你们来说可能比较熟悉。
提示 对于 .NET 开发人员,请注意 SQL Server 不支持 FINALLY 块,FINALLY 是 .NET 语言中该结构的第三个部分,允许无论 TRY 块成功或失败都运行代码。
在 TRY..CATCH 块中,SQL Server 将尝试执行 TRY 块中的代码。如果代码成功完成,则 SQL Server 将退出该结构。然而,如果发生错误,SQL Server 将在导致错误的行跳出 TRY 块并进入 CATCH 块。然后将执行 CATCH 块中的代码。
这意味着我们可以尝试执行代码,但如果失败,我们可以在 CATCH 块中放入错误处理逻辑。这个逻辑可以包括回滚事务和抛出有意义的错误。
在 SQL Server 中有两种方法可以抛出有意义的错误。第一种方法是调用 RAISERROR() 函数。第二种是一个更简单的错误处理特性,称为 THROW。虽然这两种功能都是用来引发错误的,但它们之间存在差异,我们将在下面探讨。
提示:你发现 RAISERROR() 中的错误了吗?如果没有,再看看。有一个拼写错误。但这个错误不在这本书中;它在 SQL Server 中。它可能是业界最著名、绝对也是最讽刺的拼写错误!
在 CATCH 块的上下文中,我们可以访问揭示已发生错误信息的系统函数。具体而言,可用的函数,每个函数都有一个直观的名称,是
- ERROR_NUMBER()—返回导致 CATCH 块执行的错误编号
- ERROR_SEVERITY()—返回错误的严重级别
- ERROR_STATE()—返回错误的状态编号,可帮助识别错误的原因
- ERROR_MESSAGE()—返回错误消息的完整文本
- ERROR_PROCEDURE()—返回发生错误的存储过程或触发器的名称
- ERROR_LINE()—返回错误发生的存储过程或触发器中的行号
这些函数可用于增强错误处理逻辑。例如,我们可以根据错误编号在 CATCH 块中分支代码。我们还可以将这些数据推送到错误日志表中。
让我们看看如何增强我们的存储过程以使用 TRY..CATCH 块。在我们开始事务后,我们将开始一个 TRY 块,其中包含我们的业务逻辑。TRY 块中的最后一条语句将提交我们的事务。
TRY 块紧跟着一个 CATCH 块,里面包含我们的错误处理逻辑。在这里,我们回滚事务,然后使用 THROW 命令抛出一个错误。
我们可以使用 THROW 命令的方式有两种。我们可以单独使用关键字 THROW,这将导致原始错误被抛出。或者,我们可以通过在 THROW 语句中添加自定义的错误编号、错误消息和状态来抛出特定的错误。THROW 语句无法做的是抛出存储在 sys.messages 表中的错误消息,而且我们不能指定错误的严重性。由 THROW 命令引发的错误的严重性始终为 16 级,这意味着它不会被记录。
错误严重性等级 在 SQL Server 中,有 25 个错误严重性级别。严重性级别 0 到 10 并不是真正的错误。相反,它们是信息性消息。严重性级别为 10 的错误是信息性消息,为了兼容性,它们会被转换为严重性级别 0。 严重性级别为11到16的错误被视为用户可以修复的错误,例如对象名称不正确、语法错误、权限拒绝错误和死锁。 错误严重级别17到19通常是只能由管理员修复的错误,例如资源耗尽、超出数据库引擎强制执行的限制,以及数据库引擎内部的问题导致语句执行失败但与实例的连接未关闭。 严重性级别为 20 到 24 的错误是致命错误,例如遇到数据库或媒体损坏。严重性级别为 19 到 24 的错误会被写入错误日志。 在考虑错误处理时,有几个关于严重性级别的事项我们需要记住。首先,只有严重性为11到19的错误才会导致代码执行转到CATCH块。如果抛出的错误严重性为0到10,那么执行将会继续,因为该错误只是信息性的。另一方面,如果严重性为20或以上,那么转到CATCH块就没有意义,因为该错误是致命的,在许多情况下,连接甚至会被终止。 接下来需要记住的是,如前所述,由 THROW 引发的错误具有固定的严重性为 16,这意味着它们永远不会被写入错误日志,这在许多情况下会使试图进行故障排除的人无法看清这些错误。 THROW 只能抛出原始系统错误或临时错误,这意味着该错误未存储在 sys.messages 中。因此,我们抛出的错误编号必须是 50,000 或更高。 最后,我们需要牢记,尽管每个严重性级别都有其定义的含义(例如,严重性级别22意味着表或索引已被硬件或软件问题破坏),这些级别只适用于系统错误。完全有可能创建自定义错误消息并为了我们的目的“劫持”一个错误严重性,而这可能与预期的严重性级别不符。当然,这并不是一个好的做法,因为这可能会引起同事的混淆。
列表 7.6 中的脚本显示了更新后的存储过程定义,该定义已经封装在 TRY..CATCH 块中。如果 TRY 块中的代码执行失败,那么执行将跳转到 CATCH 块,在那里事务将被回滚,然后使用 THROW 语句抛出错误。
ALTER PROCEDURE dbo.InsertSalesOrder @SalesOrderNumber NVARCHAR(12), @SalesOrderDate DATE, @SalesPersonID INT, @SalesAreaID INT, @CustomerID INT, @SalesOrderDeliveryDueDate DATE, @SalesOrderDeliveryActualDate DATE, @CurrierUsedForDelivery NVARCHAR(32), @ProductID INT, @Quantity INT AS BEGIN BEGIN TRANSACTION BEGIN TRY DECLARE @CustomerPrefix NVARCHAR(12) ; SET @CustomerPrefix = ( SELECT SUBSTRING(CustomerCompanyName,1,3) FROM dbo.Customers WHERE CustomerID = @CustomerID ) ; INSERT INTO dbo.SalesOrderHeaders VALUES ( @CustomerPrefix + @SalesOrderNumber , @SalesOrderDate , @SalesPersonID , @SalesAreaID , @CustomerID , @SalesOrderDeliveryDueDate , @SalesOrderDeliveryActualDate , @CurrierUsedForDelivery ) ; INSERT INTO dbo.SalesOrderDetails ( ProductID , Quantity , SalesOrderNumber ) VALUES ( @ProductID , @Quantity , @CustomerPrefix + @SalesOrderNumber ) ; COMMIT END TRY BEGIN CATCH ROLLBACK ; THROW ; END CATCH END
然而,到目前为止,这并没有给我们带来巨大的好处。如果我们再次执行清单 7.4 中的命令,我们将收到以下错误:
消息 2627,级别 14,状态 1,过程 dbo.InsertSalesOrder,第 23 行 [批处理开始行 0] 违反主键约束 ‘PK__SalesOrd__CF6C70EEA96DBC48’。无法在对象 ‘dbo.SalesOrderHeaders’ 中插入重复键。重复键值为 (Coo1655D-U06)。
因此,让我们进一步增强我们的 InsertSalesOrder 存储过程。清单 7.7 中的脚本将再次更新该存储过程。这一次,我们将在 CATCH 块中使用 IF 语句分支代码,并结合暴露错误信息的系统函数,使 CATCH 块根据抛出的错误表现不同。如果错误是主键冲突,将抛出自定义错误消息。如果错误是死锁,则使用 GOTO 命令尝试再次执行 TRY 块中的代码。如果抛出任何其他错误,则将抛出原始错误。
ALTER PROCEDURE dbo.InsertSalesOrder @SalesOrderNumber NVARCHAR(12), @SalesOrderDate DATE, @SalesPersonID INT, @SalesAreaID INT, @CustomerID INT, @SalesOrderDeliveryDueDate DATE, @SalesOrderDeliveryActualDate DATE, @CurrierUsedForDelivery NVARCHAR(32), @ProductID INT, @Quantity INT AS BEGIN BEGIN TRANSACTION RETRY: BEGIN TRY DECLARE @CustomerPrefix NVARCHAR(12) ; SET @CustomerPrefix = ( SELECT SUBSTRING(CustomerCompanyName,1,3) FROM dbo.Customers WHERE CustomerID = @CustomerID ) ; INSERT INTO dbo.SalesOrderHeaders VALUES ( @CustomerPrefix + @SalesOrderNumber , @SalesOrderDate , @SalesPersonID , @SalesAreaID , @CustomerID , @SalesOrderDeliveryDueDate , @SalesOrderDeliveryActualDate , @CurrierUsedForDelivery ) ; INSERT INTO dbo.SalesOrderDetails ( ProductID , Quantity , SalesOrderNumber ) VALUES ( @ProductID , @Quantity , @CustomerPrefix + @SalesOrderNumber ) ; COMMIT END TRY BEGIN CATCH IF ERROR_NUMBER() = 2627 BEGIN ROLLBACK ; THROW 50001, ‘A duplicate sales order has been entered.’, 1 ; END IF ERROR_NUMBER() = 1205 BEGIN ROLLBACK ; GOTO RETRY ; END IF ERROR_NUMBER() 2627 AND ERROR_NUMBER() 1205 BEGIN ROLLBACK ; THROW ; END END CATCH END
如果我们再次执行清单 7.4 中的命令,我们现在将收到以下错误:
消息 50001,级别 16,状态 1,过程 dbo.InsertSalesOrder,第 52 行 [批处理开始行 0] 已输入重复的销售订单。
为了最好地利用 SQL Server 的错误处理功能,我们可能希望将 THROW 与 RAISERROR() 混合使用。例如,在我们的场景中,如果发生通用错误,我们可能希望继续使用 THROW,以便原始错误信息能够冒泡出来。然而,对于主键冲突,我们可能会选择使用 RAISERROR(),以便能够将错误发送到错误日志中。
如果我们想采用这种方法,我们首先需要创建一个自定义错误消息,该消息可以通过 RAISERROR() 引发。为此,我们将使用 sp_addmessage 系统存储过程,如下列清单所示。
EXEC sp_addmessage @msgnum = 50001 , @severity = 16 , @msgtext = ‘A duplicate sales order has been entered.’ ;
然后可以更新 InsertSalesOrder 过程以调用 RAISERROR(),如清单 7.9 所示。WITH LOG 语法将导致错误被写入 SQL Server 错误日志,尽管严重性仅为 16。
ALTER PROCEDURE dbo.InsertSalesOrder @SalesOrderNumber NVARCHAR(12), @SalesOrderDate DATE, @SalesPersonID INT, @SalesAreaID INT, @CustomerID INT, @SalesOrderDeliveryDueDate DATE, @SalesOrderDeliveryActualDate DATE, @CurrierUsedForDelivery NVARCHAR(32), @ProductID INT, @Quantity INT AS BEGIN BEGIN TRANSACTION RETRY: BEGIN TRY DECLARE @CustomerPrefix NVARCHAR(12) ; SET @CustomerPrefix = ( SELECT SUBSTRING(CustomerCompanyName,1,3) FROM dbo.Customers WHERE CustomerID = @CustomerID ) ; INSERT INTO dbo.SalesOrderHeaders VALUES ( @CustomerPrefix + @SalesOrderNumber , @SalesOrderDate , @SalesPersonID , @SalesAreaID , @CustomerID , @SalesOrderDeliveryDueDate , @SalesOrderDeliveryActualDate , @CurrierUsedForDelivery ) ; INSERT INTO dbo.SalesOrderDetails ( ProductID , Quantity , SalesOrderNumber ) VALUES ( @ProductID , @Quantity , @CustomerPrefix + @SalesOrderNumber ) ; COMMIT END TRY BEGIN CATCH IF ERROR_NUMBER() = 2627 BEGIN ROLLBACK ; RAISERROR(50001, 16, 1) WITH LOG ; END IF ERROR_NUMBER() = 1205 BEGIN ROLLBACK ; GOTO RETRY ; END IF ERROR_NUMBER() 2627 AND ERROR_NUMBER() 1205 BEGIN ROLLBACK ; THROW ; END END CATCH END
如果我们随后再次执行清单 7.4 中的命令,我们的自定义错误不仅会返回给客户端,而且也会被写入 SQL Server 错误日志,如图 7.1 所示。
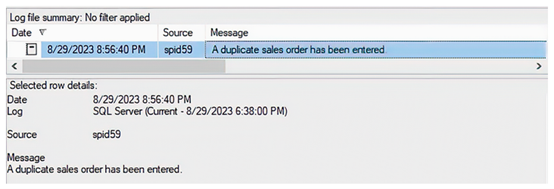
使用 RAISERROR() WITH LOG 的替代方法是使用自定义错误表。例如,清单 7.10 中的脚本首先创建了一个错误日志表。然后它再次更新存储过程,将其恢复为使用 THROW。不过这一次,它更新了 CATCH 块,将错误记录到我们新创建的表中。
CREATE TABLE dbo.ErrorLog ( ID INT PRIMARY KEY IDENTITY, ErrorMessage NVARCHAR(MAX), ErrorNumber INT, ErrorSeverity INT ) ; GO ALTER PROCEDURE dbo.InsertSalesOrder @SalesOrderNumber NVARCHAR(12), @SalesOrderDate DATE, @SalesPersonID INT, @SalesAreaID INT, @CustomerID INT, @SalesOrderDeliveryDueDate DATE, @SalesOrderDeliveryActualDate DATE, @CurrierUsedForDelivery NVARCHAR(32), @ProductID INT, @Quantity INT AS BEGIN BEGIN TRANSACTION RETRY: BEGIN TRY DECLARE @CustomerPrefix NVARCHAR(12) ; SET @CustomerPrefix = ( SELECT SUBSTRING(CustomerCompanyName,1,3) FROM dbo.Customers WHERE CustomerID = @CustomerID ) ; INSERT INTO dbo.SalesOrderHeaders VALUES ( @CustomerPrefix + @SalesOrderNumber , @SalesOrderDate , @SalesPersonID , @SalesAreaID , @CustomerID , @SalesOrderDeliveryDueDate , @SalesOrderDeliveryActualDate , @CurrierUsedForDelivery ) ; INSERT INTO dbo.SalesOrderDetails ( ProductID , Quantity , SalesOrderNumber ) VALUES ( @ProductID , @Quantity , @CustomerPrefix + @SalesOrderNumber ) ; COMMIT END TRY BEGIN CATCH IF ERROR_NUMBER() = 2627 BEGIN ROLLBACK ; INSERT INTO dbo.ErrorLog (ErrorMessage, ErrorNumber,ErrorSeverity) SELECT ERROR_MESSAGE() , ERROR_NUMBER() , ERROR_SEVERITY() ; THROW 50001, ‘A duplicate sales order has been entered.’, 1 ; END IF ERROR_NUMBER() = 1205 BEGIN ROLLBACK ; GOTO RETRY ; END IF ERROR_NUMBER() 2627 AND ERROR_NUMBER() 1205 BEGIN ROLLBACK ; THROW ; END END CATCH END
警告 如果我们采用自定义错误记录方法,那么语句的顺序就非常重要。INSERT 语句必须在 ROLLBACK 之后且在 THROW 之前。如果 INSERT 在 ROLLBACK 之前,那么它将成为事务的一部分,因此会随着 TRY 块中的代码一起回滚。如果 INSERT 在 THROW 语句之后,它将不会被执行。
我们应该考虑在修改数据的代码中添加错误处理。这使我们能够回滚事务并提出有意义的错误信息。我们还应该考虑在适当的地方记录错误信息。在某些情况下,例如死锁,我们甚至可能希望在我们的程序中编写重试逻辑。
错误27# 未能对错误发出警报
一旦我们的存储过程投入生产,根据代码的性质,它可能有多种执行方式。它可以由 ETL 工具执行,例如 SSIS;也可以由 SQL Server Agent 作业执行,后者是一系列可按计划在特定时间运行的协调操作;或者它可以被客户端应用程序调用。
如果一个过程被客户端应用程序调用,并且如果该应用程序编写良好,错误应该会向上冒泡到用户并被注意到。然而,如果该过程被自动化流程调用,那么它可能不易被发现。需要应用支持人员主动检查 SQL Server Agent 日志、SSISDB 日志或自定义日志表以发现故障。
提示 如前一节所讨论的,根据错误的严重程度以及引发错误的方法,错误可能不会记录在 SQL Server 错误日志中。这使得错误日志成为检查应用程序错误的不可靠场所。
主动检查通常不会进行,即使进行了,也会受到人为错误和机会成本的影响,这意味着有人在花时间执行琐碎任务,而不是进行更高价值的工作。所有这些都意味着,很容易出现故障而未被发现,直到用户报告数据看起来不正确。
那么我们如何解决这个问题呢?答案是告警。如果我们观察 IT 基础设施堆栈的任何层,从网络层到操作系统,支持团队通常都会设置告警,以在发生需要他们调查或采取行动纠正的错误时通知他们。然而,当涉及到数据层应用程序时,告警往往被忽视,这是一个错误。
根据我们应用程序的规模和优先级,我们可能幸运地拥有企业级可观测性软件,例如 SolarWinds 或 LogicMonitor。如果是这种情况,那么我们应该使用该软件创建一个自定义检查,以在发生故障时发出警报。如果我们选择这条路径,那么我们的自定义数据源通常会被编写为定期从日志表中读取数据,并在日志中写入错误时发出警报。当使用 SSISDB 中的自定义日志记录和日志表时,这通常只涉及一个简单的 SELECT 语句。然而,如果我们需要从 SQL Server Agent 日志中读取信息,则需要使用 sp_help_jobsteplog 存储过程。例如,如果我们有一个名为 Populate_Fact_Tables 的 SQL Server Agent 作业,那么我们可以使用以下命令来获取该步骤的日志信息:
EXEC msdb.dbo.sp_help_jobhistory @job_name = ‘Populate_Fact_Tables’ , @mode = ‘FULL’ ;
如果我们没有足够幸运拥有可以用来生成警报的企业级监控工具,那么我们可以使用 SQL Server 的内置功能。在这种情况下,我们将使用一个称为数据库邮件的功能,以及 SQL Server Agent 警报子系统。
数据库邮件 值得在此指出的是,Database Mail 在社区中备受非议,因为它并不是企业级工具。虽然我大体上同意这一评价,但坦白说,如果我们的组织没有投资购买可以完成工作的第三方工具,那么我们就需要利用现有的资源,而我曾多次处于这种情况。 关于这一功能的主要抱怨之一是它无法扩展。该功能位于 msdb 中,在当今复杂的 SQL Server 环境中,故障切换事件可能导致该工具无法正常工作。 通过引入封闭的可用性组,这个问题在一定程度上得到了缓解,封闭的可用性组包含它们自己的 master 和 msdb 系统数据库副本。然而,在撰写时,而且希望在阅读时不是这样,封闭的可用性组中存在一个错误,导致数据库邮件功能无法正常工作。 同样值得注意的是,要使用该功能,我们将需要访问SMTP中继服务器。数据库邮件本身没有内置SMTP服务。它需要通过现有的SMTP服务来发送邮件。 对数据库邮件的全面讨论超出了本书的范围,但可以在 https://mng.bz/PND9 找到更多详细信息。
让我们来探讨如何创建一个在出现错误消息时触发的警报。假设数据库邮件已经配置好,我们需要创建两个对象。第一个是操作员,将配置为使用数据库邮件配置文件,第二个是警报本身。
需要注意的是,SQL Server Agent 警报依赖于 Windows 应用程序日志来知道 SQL Server 何时触发了事件。当事件被写入 SQL Server 错误日志时,会将其转发到应用程序日志。因此,如果某个事件没有创建日志条目,则不会触发警报。这意味着当我们使用这种方法时,必须确保使用带有 LOG 选项的 RAISERROR() 提升错误消息。这意味着它们将被记录,即使严重性级别低于 19,也会触发警报。
让我们使用清单 7.11 中的脚本来创建一个名为 Pete 的操作员,如果触发警报,他将收到通知。
提示 在现实场景中,我们更倾向于使用群组电子邮件地址或分发列表。
EXEC msdb.dbo.sp_add_operator @name= ‘Pete’ , @enabled=1 , @email_address= ‘[email protected]’ ;
提示 SQL Server 目前支持寻呼通知以及电子邮件,前提是我们有第三方寻呼到电子邮件的软件。然而,这个功能已经弃用,不应使用。
要创建警报,我们可以在 SSMS 中 SQL Server 代理下的警报节点的上下文中选择“新建警报”。这将显示“新建警报”对话框。该对话框的常规页如图 7.2 所示。在这里,我们为警报命名,并指定希望其响应 SQL Server 事件。其他选项是使警报响应 WMI 事件或 SQL Server 性能条件。在“数据库名称”下拉列表中,我们可以保留默认的所有数据库,也可以选择必须触发警报的特定数据库。最后,我们可以选择警报是响应特定错误号还是特定严重性级别触发。
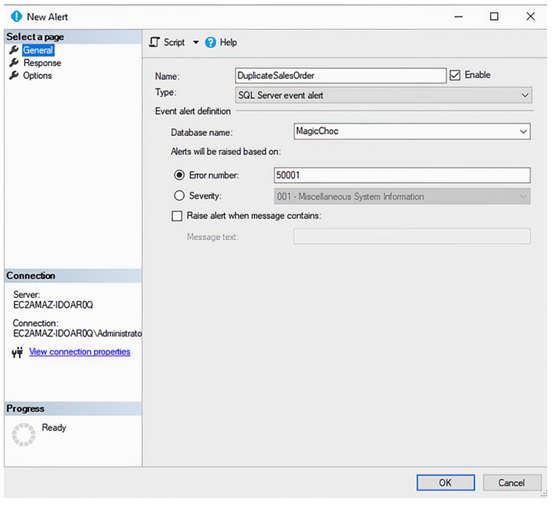
在对话框的响应页面中,我们可以选择是否在收到警报时执行 SQL Server Agent 作业,这将尝试解决问题,或者我们是否想向操作员发送警报,或者两者都做。出于我们的目的,我们将勾选“通知操作员”选项。这将使操作员列表变为可用,并且我们可以在 Pete 操作员旁选择电子邮件。
在对话框的“选项”页面上,我们可以创建附加的通知文本,这些文本将随电子邮件发送。我们还可以指定发送警报之间的延迟。此功能可用于在警报快速连续触发时减少噪音警报。
或者,我们可以不用 GUI,而是在 msdb 数据库中使用 sp_add_alert 和 sp_add_notification 存储过程来创建警报。下面的列表展示了这一点。
EXEC msdb.dbo.sp_add_alert @name= ‘DuplicateSalesOrder’ , @message_id=50001 , @enabled=1 , @database_name= ‘MagicChoc’ ; EXEC msdb.dbo.sp_add_notification @alert_name= ‘DuplicateSalesOrder’ , @operator_name= ‘Pete’ , @notification_method = 1 ;
我们应该始终考虑为通过自动化流程运行的数据层应用程序中的代码创建警报。理想情况下,这些警报应在企业级可观测性工具中创建。然而,如果没有这种工具,我们可以使用 SQL Server Agent 警报和数据库邮件通过现有的 SMTP 服务器发送警报。
错误28# 未使用调试功能
来自 .NET 背景的你们可能对 Visual Studio 中可用的大量调试工具非常熟悉。许多这些功能在 SQL Server 开发中也可用,但不熟练的 T-SQL 开发人员很少使用它们。这通常是因为对功能集不熟悉,但不使用它们只能被称为一个错误。
我曾见过开发人员为找到自己编写的存储过程中的错误而抓狂。他们反复执行存储过程,注释掉查询并插入 PRINT 语句。他们创建变量来模拟存储过程的参数,并在代码中运行单独的查询,拼命试图找出错误所在。在开发的这个阶段花费的时间有时甚至和创建存储过程本身一样长,这并不罕见。
如果 T-SQL 开发人员结合使用 Visual Studio 的调试功能和 SQL Server 数据库项目模板,他们可以节省大量时间。要跟随本节中的示例操作,你应该创建一个名为 Marketing 的 SQL Server 数据库项目,然后导入我们在第 6 章创建的 Marketing 数据库。你可以通过 Marketing 项目的上下文菜单中的 Project | Import | Database 选项来导入数据库。你需要创建一个连接。
一旦项目配置完成,让我们向项目添加一个新项目,并使用清单 7.13 中的定义创建一个存储过程。该存储过程接受 CampaignID 和 Budget 参数,并使用这些参数创建广告活动摘要。将生成两个结果集。第一个是广告活动的财务摘要,第二个是 ReferralURL 和 RenderingID 的唯一列表。
CREATE PROCEDURE dbo.CalculateCampaignSummary @CampaignID INT, @Budget MONEY AS BEGIN DECLARE @AvgCPM DECIMAL ; DECLARE @CampaignCost MONEY ; DECLARE @NoOfImp INT ; DECLARE @AvgBidPrice MONEY ; DECLARE @CostOfBidPerc DECIMAL ; DECLARE @BudgetDifference MONEY ; SELECT @NoOfImp = COUNT(*) , @CampaignCost = (SUM(CostPerMille) / 1000) * COUNT(*) FROM marketing.Impressions WHERE CampaignID = @CampaignID GROUP BY CampaignID ; SELECT @avgcpm = AvgCostPerMille , @avgbidprice = AvgBidPrice FROM reporting.ImpressionAggregates WHERE CampaignID = @CampaignID ; SET @CostOfBidPerc = (@AvgBidPrice / @AvgCPM) * 100 ; SET @BudgetDifference = @budget – @CampaignCost ; SELECT @CampaignID CampaignID , @AvgCPM AvgCPM , @CampaignCost CampaignCost , @NoOfImp ImpQty , @CostOfBidPerc CostToBidPercentage , @BudgetDifference ; SELECT DISTINCT ReferralURL , RenderingID FROM marketing.Impressions WHERE CampaignID = @CampaignID ; END
我们首先要讨论的调试工具是“错误列表”窗口,可以在“视图”菜单中找到。这个窗口非常有用,它可以实时分析我们的代码,并报告构建错误和 IntelliSense 错误。例如,如果我在最终查询和 END 语句之间向我们的代码中添加文本“让我们添加一个错误”,那么“错误列表”窗口会在片刻之内更新,如图 7.3 所示。

现在让我们发布我们的数据库。我们可以通过在项目的上下文菜单中选择“发布”来做到这一点。在“发布数据库”对话框中,选择我们之前创建的指向服务器上营销数据库的连接。这将导致我们的存储过程被部署到我们的 SQL Server 实例中。
注意 如果您像我一样插入了错误的文本,您需要在发布前将其删除;否则,构建将失败。
现在让我们使用清单 7.14 中的命令执行我们新的存储过程。请在 SQL Server 对象资源管理器中从 SQL Server 实例的上下文菜单中打开一个新的查询窗口,并使用查询窗口任务栏上的浅绿色开始按钮执行该过程。
USE Marketing ; GO EXEC dbo.CalculateCampaignSummary 22961, 52 ;
在这一时刻,我们会看到该过程在第26行抛出除以零的错误。
所以让我们再次执行存储过程;但这次让我们使用调试器。如果我们点击浅绿色开始按钮旁边的下拉菜单,就会看到一个额外的选项。这个选项由一个深绿色的播放按钮表示,标签为“使用调试器执行”。
当我们选择此选项时,执行将开始,但第一条语句(在我们的例子中是 USE Marketing 语句)将被标记为黄色。这表示执行在此处暂停。我们现在有几种选项,表 7.1 中有说明。
| Option | Shortcut | Description |
| Continue | F5 | Continue execution until the next breakpoint.* |
| Step Over | F10 | Will step through the top layer of code but continue through lower levels, such as procedures or functions, without debugging them (unless a breakpoint is hit)* |
| Step Into | F11 | Will step through all layers of code. When a procedure or function is encountered, it will step into that code block and pause execution at the first statement. |
由于我们需要调试存储过程,最合适的选择是“逐过程执行”。所以让我们使用 F11 逐过程执行我们的存储过程。当我们逐条执行每个查询时,会注意到在“本地变量”窗口中每个变量(和参数)的值被更新。在前两条查询运行完之后,“本地变量”窗口应该看起来类似于图 7.4。
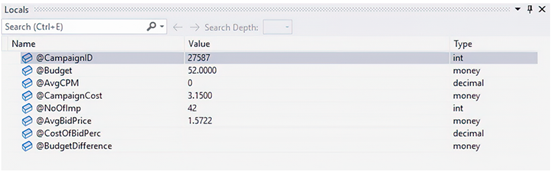
我们现在可以看到除以零错误的原因。@AvgCPM 变量的值为 0,下一条语句将用这个值去除 @AvgBidPrice。让我们试着弄清楚原因。在不暂停执行的情况下,我们可以在即时窗口中运行查询。让我们使用即时窗口运行以下清单中的查询,这将确保我们只返回过程中的第二个查询的一行数据。
SELECT COUNT(*) FROM reporting.ImpressionAggregates WHERE CampaignID = @CampaignID
这返回数字 42。嗯,这就解释清楚了!我们程序中的第二个查询返回 42 行,或者换句话说,我们正试图将 42 个不同的值分配给我们的每一个变量。
额外错误 对于那些可能想知道为什么 @AvgCPM 和 @AvgBidPrice 表现不同的人,请查看数据类型。@AvgCPM 是 DECIMAL,而 @AvgBidPrice 是 MONEY。因此,@AvgBidPrice 使用的是要返回的最终值。 这是我在创建这些示例时无意中犯的一个错误,这就是为什么它没有出现在调试示例中的原因。我决定保留它,因为这种行为实际上相当有趣,可能不是你所预期的,但我们也应该将 @AvgCPM 设置为 MONEY。
我们最好更新存储过程中第二个查询以获取平均值,这正是我们所需要的。我们可以通过在以下列表中发布过程定义来实现这一点。
CREATE PROCEDURE dbo.CalculateCampaignSummary @CampaignID INT, @Budget MONEY AS BEGIN DECLARE @AvgCPM MONEY ; DECLARE @CampaignCost MONEY ; DECLARE @NoOfImp INT ; DECLARE @AvgBidPrice MONEY ; DECLARE @CostOfBidPerc DECIMAL ; DECLARE @BudgetDifference MONEY ; SELECT @NoOfImp = COUNT(*) , @CampaignCost = (SUM(CostPerMille) / 1000) * COUNT(*) FROM marketing.Impressions WHERE CampaignID = @CampaignID GROUP BY CampaignID ; SELECT @avgcpm = AVG(AvgCostPerMille) , @avgbidprice = AVG(AvgBidPrice) FROM reporting.ImpressionAggregates WHERE CampaignID = @CampaignID ; SET @CostOfBidPerc = (@AvgBidPrice / @AvgCPM) * 100 ; SET @BudgetDifference = @budget – @CampaignCost ; SELECT @CampaignID CampaignID , @AvgCPM AvgCPM , @CampaignCost CampaignCost , @NoOfImp ImpQty , @CostOfBidPerc CostToBidPercentage , @BudgetDifference ; SELECT DISTINCT ReferralURL , RenderingID FROM marketing.Impressions WHERE CampaignID = @CampaignID ; END
注意:对于 SQL Server 数据库项目,即时窗口确实存在一些限制。具体来说,我们无法运行任何需要加载执行环境的内容。一般而言,这意味着我们可以返回标量值,例如计数,但不能返回结果集。这也意味着某些其他功能,例如像 ERROR_NUMBER() 或 ERROR_MESSAGE() 这样的系统函数,是不可用的。然而,系统变量仍然可用。因此,例如,我们可以执行 SELECT @@trancount。
既然我们已经修复了存储过程,让我们再次以调试模式运行它。但在此之前,让我们快速聊一下断点。断点是代码中的一个点,开发人员在此指出希望执行暂停。这是在调试代码时非常有用的功能,因为它允许开发人员执行诸如检查变量值和确定逻辑中的执行路径等操作。
既然我们知道了断点是什么,让我们在第26行设置一个断点(SET @CostOfBidPerc = (@AvgBidPrice / @AvgCPM) * 100 ;)。我们可以通过简单地点击左侧边缘,在我们希望发生中断的位置旁边,来创建一个简单的断点。如果我们现在开始调试存储过程,并使用F5而不是F11,执行将会持续进行直到断点被触发。此时,我们可以在本地变量窗口检查我们的@AvgCPM和@AvgBidPrice变量是否具有预期值,然后再次按F5以允许执行完成。
警告 Visual Studio 支持高级断点,这使我们可以为断点添加条件。然而,T-SQL 不支持这些条件。
在 Visual Studio 的 SQL Server 数据库项目模板中使用现代调试技术来调试代码。这可以节省时间,并使调试代码的过程不那么令人沮丧。
错误29# 未使用模式比较
当我们对一个复杂的可编程对象进行大幅修改时,很难跟踪我们所做的事情。我经常看到 T-SQL 开发人员犯的一个错误是,在没有完全理解将要更改内容的情况下,将大量代码更改部署到他们的环境中。这是一个可能导致生产环境出现多种问题的错误。
此外,糟糕的变更和部署流程,结合紧急修复,可能导致不同环境之间的代码漂移。例如,如果我们有一个开发环境、一个测试环境、一个预发布环境和一个生产环境,就可能会出现部署顺序混乱的情况。
为了避免这些问题,开发人员可以使用 SSDT 架构比较工具。这是一种可以比较两个不同环境中的数据库并突出显示它们之间差异的工具。我们也可以选择使用架构比较工具将数据库同步。
为探讨这一点,让我们更新营销项目中的 CalculateCampaignSummary 存储过程。我们的汇总中缺少 @BudgetDifference 的别名,同时我们还想添加一个参数来控制是否返回第二个结果集。我们可以使用下一个列表中的脚本对定义进行更改。保存更改,但暂时不要发布。
CREATE PROCEDURE dbo.CalculateCampaignSummary @CampaignID INT, @Budget MONEY, @Detailed BIT AS BEGIN DECLARE @AvgCPM MONEY ; DECLARE @CampaignCost MONEY ; DECLARE @NoOfImp INT ; DECLARE @AvgBidPrice MONEY ; DECLARE @CostOfBidPerc DECIMAL ; DECLARE @BudgetDifference MONEY ; SELECT @NoOfImp = COUNT(*) , @CampaignCost = (SUM(CostPerMille) / 1000) * COUNT(*) FROM marketing.Impressions WHERE CampaignID = @CampaignID GROUP BY CampaignID ; SELECT @avgcpm = AVG(AvgCostPerMille) , @avgbidprice = AVG(AvgBidPrice) FROM reporting.ImpressionAggregates WHERE CampaignID = @CampaignID ; SET @CostOfBidPerc = (@AvgBidPrice / @AvgCPM) * 100 ; SET @BudgetDifference = @budget – @CampaignCost ; SELECT @CampaignID CampaignID , @AvgCPM AvgCPM , @CampaignCost CampaignCost , @NoOfImp ImpQty , @CostOfBidPerc CostToBidPercentage , @BudgetDifference BudgetDifference$ ; IF @Detailed = 1 BEGIN SELECT DISTINCT ReferralURL , RenderingID FROM marketing.Impressions WHERE CampaignID = @CampaignID ; END END
在部署我们更新的过程之前,我们可以分析我们所做的更改。为此,在 Visual Studio 的 SQL Server 对象资源管理器中,在 Marketing 项目的上下文菜单中选择“模式比较”。这将会显示一个比较窗口,我们可以使用右上角的“选择目标”来选择我们实例中的 Marketing 数据库。点击比较窗口任务栏顶部的比较按钮,现在将执行比较。
此比较的结果显示在图7.5中。
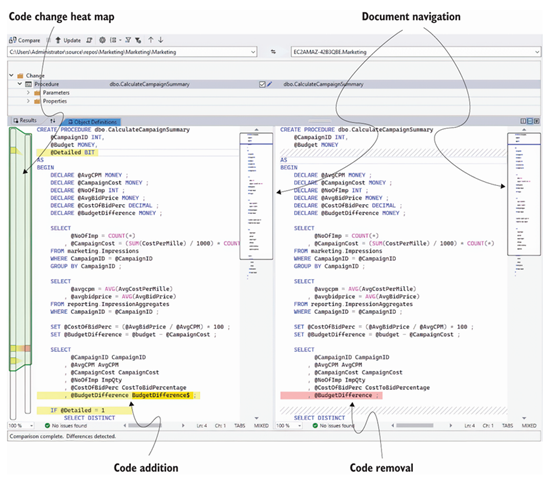
窗口顶部的窗格显示了每个已更改的对象,如果我们选择一个对象,源和目标的定义将显示在下方的窗格中。
您会注意到,新增的内容会以黄色突出显示,删除的内容会以红色标记。下方窗格左侧的条显示了代码中发生更改的位置,我们可以点击该条以移动到感兴趣的区域。源代码和目标窗格右侧的框显示当前屏幕上可见的代码部分。这个框也是可点击的,允许我们移动到不同的位置。
窗口顶部的任务栏为我们提供了更新目标和生成更新脚本的按钮。一个选项按钮允许我们设置对象排除规则,并定义应忽略的任何差异。分组对象按钮将切换对象按类型和模式的分组,还存在用于切换显示不支持的操作和未更改对象的按钮。我们还可以使用上下箭头按钮在更改的对象之间移动。
在更改大型复杂对象时,我们应在部署前使用模式比较,以确保我们完全理解所做的更改,并且不会覆盖尚未回到部署周期的紧急修复。
错误30# 未能编写单元测试
开发者会破坏东西。这是事实。无论我们多么优秀,总是存在风险:当我们修改某些代码以增加额外功能,甚至只是为了修复现有功能中的一个错误时,可能会破坏其他东西。这可能由多种原因造成,从简单的错误到不了解某个代码模块的完整功能和目的。
在一个老式的 SQL Server 开发环境中,尤其是一个多年来自然发展起来的环境中,仍然在数据层应用程序上工作的开发人员很可能不会完全了解大型应用程序中每个代码模块所满足的每个需求。在大型复杂项目中,这一情况尤为真实。
解决这个问题的方法是编写单元测试。单元测试旨在测试特定的功能。这带来了两个主要好处。首先,它可以防止开发人员在更新代码模块时无意中破坏现有功能。其次,本着自我文档化的精神,它在业务需求与代码模块之间创建了一个映射。
在现代开发时代,不编写单元测试是一种错误——但这是我在 SQL Server 社区中经常看到的错误。如果数据层应用程序是通过敏捷项目方法交付的,这就是一个更大的错误。在敏捷方法中,例如 Scrum 或 Kanban,应用程序是通过小的迭代周期交付的。这对项目有多种好处,例如能够更早交付最小可行产品,并且使项目更容易调整以满足不断变化的业务需求。
然而,采用这种项目方法,我们以后更有可能需要重新访问更多的代码模块,这增加了破坏之前编写的功能的风险。这使得单元测试变得更加重要。
现实世界的例子 在2000年至2010年代期间,我有幸领导了当时伦敦开发的一些最大的数据库级应用程序的开发。这段时期的方法论差异非常显著。这些项目的第一个和最后一个都是多年项目,涉及多家公司,巅峰时期开发人员超过20人。它们都处理了40到50 TB的数据,这需要复杂的处理。 一个项目涉及从两个搜索引擎和四个 Cookie 服务器的不同数据源构建和分析点击路径。必须计算完整的用户旅程,从查看在线横幅或搜索引擎搜索,到实际在广告商的网站上购买产品。 另一个有复杂的数据,包括一个 30 小时的时钟和一个由 36 个重叠广告区域组成的层级结构,其中广告的观看次数必须映射到层级结构中正确的区域及正确的层级(有时是多个层级)。两个应用程序都是用 SQL Server 技术栈编写的,并且最终都超过了 100 万行代码。 这些项目中的第一个采用了传统的开发方法。我们在开发服务器上编写代码。代码模块被脚本化并存储在团队基础服务器(TFS)中。TFS 有许多功能,其中之一是悲观的源代码控制方式。我们使用手动脚本的方法将代码推广到用户验收测试(UAT)环境。然后业务部门会测试新功能,之后代码才会被手动推广到预生产环境。 直到项目的最终测试阶段,一切都很好。此时,发现了许多漏洞,因为开发人员在添加新功能的同时破坏了原有功能。没有人发现这个问题,因为在代码上线时,只测试了新功能。更糟糕的是,由于项目持续了两年多,编写部分早期代码的开发人员已经离开,我们不得不弄清模块本应做什么。结果导致上线延迟了九个月。这种情况是我绝不想再经历的! 在这些项目的最后一个项目中,吸取了教训后,我们采取了更现代的方法。我们将代码存储在 GitHub 上,以便团队能够更高效地协作(见下一节);我们还使用 Jenkins 和 Octopus Deploy 创建了 CI/CD 流水线(见第 7.6.2 节)。我们为编写的每个代码模块创建了单元测试。CI/CD 流水线会执行这些单元测试,如果测试未通过,构建就会失败。起初编写测试确实需要些额外的努力,但这意味着在项目结束时,不会有大量的漏洞积压,且项目能够按时上线。
让我们遵循良好的实践,为我们的 CalculateCampaignSummary 存储过程创建单元测试。要开始此过程,我们将在 Visual Studio 中的 SQL Server 对象资源管理器窗口中从存储过程的上下文菜单中选择“创建单元测试”选项。这将显示“创建单元测试”对话框。在该窗口的上半部分,我们可以选择对象。在下半部分,我们可以选择是否希望测试项目(将作为解决方案中的附加项目创建)以 C 为基础。
单元测试文件随后将在一个有用的编辑器中显示。如果我们有多个测试,我们可以在窗口左上方的下拉菜单中切换它们。在右侧的下拉菜单中,我们可以选择我们的预测试脚本、测试脚本或后测试脚本。
预测试脚本应用于为测试设置我们的环境。这可能包括在测试执行之前填充表等任务。我们将对我们的 SQL Server 实例运行脚本,所以我们无需创建预测试脚本。
在后置测试脚本中,我们可以进行自我清理。例如,如果我们正在测试一个用于添加销售订单的存储过程,我们可以使用后置测试脚本来删除该销售订单。
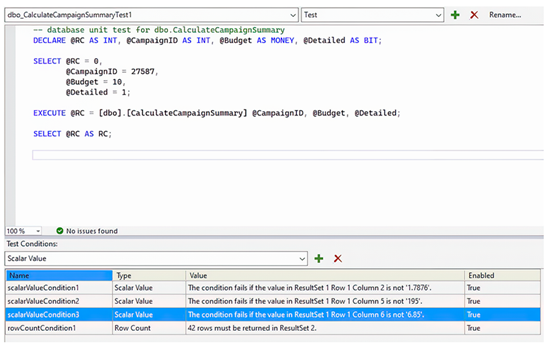
测试脚本是我们执行代码模块的地方。Visual Studio 为我们提供了代码模板,因此我们只需添加所需参数的值即可。对于我们的测试,我们将使用 CampaignID 为 27587 和 Budget 为 10,并将 Detailed 参数设置为 1。
然后我们想要创建四个测试条件。前三个将是标量值条件,我们将配置它们以检查以下是否为真:
- 第2列 = 1.7876
- 第5列 = 195
- 第6列 = 6.85
最终条件将是行数条件。此条件将确保第二个结果集返回42行。我们可以删除自动生成的不确定条件。
要删除不确定的条件,请在下方窗格中选中它,然后使用红色叉号按钮将其移除。然后,我们可以通过从下拉列表中选择所需类型,再使用绿色添加按钮来添加所需的条件。每个条件都可以通过属性窗口进行配置。图7.6显示了测试代码窗口和测试条件。
一旦我们保存了测试,我们可以通过导航到“测试资源管理器”窗口来运行它,并使用任务栏左侧的双播放按钮运行所有测试。通过点击任务栏上的漏斗按钮取消选择过滤器,将会显示所有测试及其状态。我们可以通过测试层次结构深入查看,并点击某个测试以查看详细信息。
要查看测试失败时的样子,请返回我们创建的测试,更改一个预期结果的值,然后再次运行测试。
提示:重要的是要记住,如果测试失败,代码中可能并没有错误。可能是测试本身有错误!
我们应该始终考虑为我们的 T-SQL 代码模块编写单元测试。对于包含代码分支或更新数据的模块尤其如此。这种做法可以降低因添加新功能而引入错误的风险,并通过将业务需求映射到代码模块来帮助使我们的代码自我记录。
现代开发技术
在以下章节中,我们将讨论 SQL Server 开发人员应该使用但往往不使用的现代开发技术来管理他们的代码。其中第一种技术是使用源代码控制。第二种是使用 CI/CD 流水线来管理代码部署。
但是,为什么我们要费心去使用这些技术呢?数据库专业人员一直遵循的那些旧的、熟悉的流程有什么问题吗?关于我们如何存储代码,过去很常见的情况是,生产环境之外数据库模式的唯一副本通常保存在开发服务器上。开发人员会直接在开发服务器上更新对象,直到它们被发布到生产环境中。在一些环境中,我们可能会发现,一旦创建了对象,它们会被生成脚本并以代码的形式存储到另一个平台上。有时是开发人员的计算机,有时是SharePoint,而在非常先进的环境中,这些脚本甚至可能被存储在Team Foundation Server中。
至于部署,过去开发人员通常会编写非常复杂的部署脚本,然后期望生产数据库管理员(DBA)在几乎没有上下文的情况下在实际系统上执行。所有参与者都会交叉手指,希望在部署过程中不会出现与环境相关的问题。
那么为什么这些技术会有这么多问题呢?好吧,让我们考虑以下例子。MagicChoc 的开发团队决定遵循传统的代码存储和部署机制。具体来说,他们将代码存储在开发实例上。他们认为这是可以接受的,因为他们每周都会备份开发环境,因此如果需要,可以从备份中恢复对象定义。
他们还使用手动部署流程。这涉及开发人员编写复杂的脚本,这些脚本会将数据导出到临时表,删除并重新创建表和可编程对象,然后再将数据导入回来。
他们准备将数据库的新版本部署到生产环境,因此他们将脚本发送给数据库管理员,并请他们在即将到来的维护窗口中运行脚本。当维护窗口开始时,数据库管理员启动了脚本。不幸的是,在脚本运行期间,Windows 更新启动并重启了服务器。这导致数据库处于不一致的状态。一些对象已被更新;而其他对象则没有。更糟糕的是,一些数据已经丢失。
维护窗口很短,所以空气中有一种紧张感,DBA 决定从事件发生前刚做的备份中恢复数据库。在匆忙中,他们把数据库恢复到了开发实例而不是生产实例。意识到错误后,他们也将数据库恢复到了生产环境。
开发人员理解数据库管理员的错误,并请求他们将开发数据库恢复到开发服务器上。不幸的是,当数据库管理员尝试这样做时,他们意识到开发服务器的最后一次备份失败,因此已经有 13 天没有备份了。简而言之,开发人员几乎失去了两周的工作,包括为此次发布所付出的全部努力,他们将不得不从头再来。
注意:虽然这听起来像是一个非常不可能的情景,但它是基于我的一位SQL开发朋友的经验。
那么,MagicChoc 怎么才能避免这些问题呢?简单来说,它可以使用现代开发实践。如果它将数据存储在源代码管理中,就可以非常快速和轻松地检索代码。如果它使用了 CI/CD 流水线,那么就可以从一开始就降低问题发生的风险。当然,更好的发布管理可以完全避免这些问题,但那是另一回事!
在接下来的部分中,我们将探讨 SQL Server 的 GitHub 工作流程,以及 SQL Server 部署的 CI/CD 背后的概念,以了解 MagicChoc 本可以如何做得更好。不过,我还是建议你进一步阅读这两个主题。
错误31# 不将代码保存在源代码管理中
在我们的情境中,MagicChoc 无法恢复其代码,因为它依赖的是带有备份的开发服务器。为了避免这个错误,我们的开发人员本可以将他们的代码存储在源代码管理中。
随着 Git 的发展,Git 是一个开源版本控制系统,此外,自从像 GitHub 这样的产品问世以来,GitHub 是一个用于管理 Git 仓库(repos)的 SaaS 托管服务,源代码控制现在已经成为管理和存储我们代码的更好方式。
与 Git 集成允许多个开发者并行工作在项目的相同部分上。源代码管理是乐观的,这意味着文件不会被锁定,因此仍然可能发生冲突,但这些冲突是可以管理的。我们可以访问版本历史记录,因此如果我们引入了一个错误,可以很容易地回滚。它还意味着我们在一个已知、安全、可靠的位置存储了一份代码副本。所有这些源代码管理的好处意味着在当今时代不使用它是一个明显的错误,但我仍看到许多 SQL 开发者在犯这个错误。
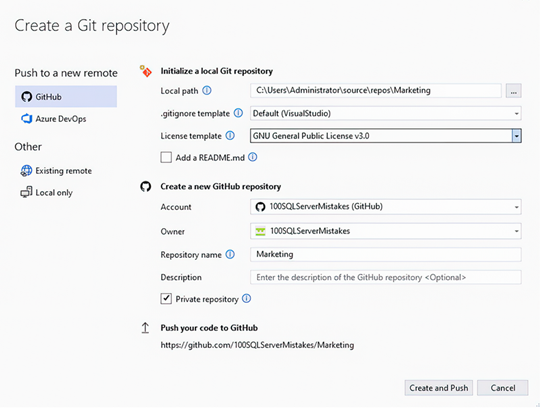
为了避免这个错误,在 Visual Studio 中的 SQL Server 数据库项目中,导航到 Git 更改窗口并选择创建 Git 仓库。这将显示创建 Git 仓库对话框。
如图 7.7 所示,屏幕的上半部分允许我们指定仓库的初始化设置——具体来说,是你计算机上仓库的本地路径、要使用的许可证模板(如果有的话)以及 gitignore 模板。这用于指定仓库内不应被 Git 跟踪的文件。在对话框的下半部分,我们指定要使用的 GitHub 账户。点击此处将启动 GitHub 登录页面。我们还将指定仓库的名称、可选的描述以及所有者。
现在我们的 GitHub 配置已经就绪,我们的第一个任务是创建一个分支。这将是我们的代码分支,在合并到主干之前,我们可以确保它是令人满意的,主干通常称为 master 或 main。我们可以通过在 Git 更改窗口顶部使用分支下拉菜单并选择“新建分支”来实现。在“创建新分支”对话框中,我们可以为分支命名(如果你想跟着操作,可以命名为 CalculateCampaignSummary)。然后我们选择要基于的分支,在我们的例子中是主干。确保勾选签出分支并跟踪远程更改的选项。
注意:在撰写本文时,master 仍然是 Git 中主分支的默认名称,但值得庆幸的是,Git 计划很快将其更改为一个更具包容性的名称。
现在让我们通过对我们的 CreateCampaignSummary 存储过程进行小的修改,来看看代码更改在实践中是如何工作的。列表 7.18 中的脚本在我们的 IF 分支周围添加了一个 BEGIN..END。
提示 在 IF 块中,如果分支中有多个语句,则 BEGIN..END 是必需的;如果只有一个语句,则可选。
CREATE PROCEDURE dbo.CalculateCampaignSummary @CampaignID INT, @Budget MONEY, @Detailed BIT AS BEGIN DECLARE @AvgCPM MONEY ; DECLARE @CampaignCost MONEY ; DECLARE @NoOfImp INT ; DECLARE @AvgBidPrice MONEY ; DECLARE @CostOfBidPerc DECIMAL ; DECLARE @BudgetDifference MONEY ; SELECT @NoOfImp = COUNT(*) , @CampaignCost = (SUM(CostPerMille) / 1000) * COUNT(*) FROM marketing.Impressions WHERE CampaignID = @CampaignID GROUP BY CampaignID ; SELECT @avgcpm = AVG(AvgCostPerMille) , @avgbidprice = AVG(AvgBidPrice) FROM reporting.ImpressionAggregates WHERE CampaignID = @CampaignID ; SET @CostOfBidPerc = (@AvgBidPrice / @AvgCPM) * 100 ; SET @BudgetDifference = @budget – @CampaignCost ; SELECT @CampaignID CampaignID , @AvgCPM AvgCPM , @CampaignCost CampaignCost , @NoOfImp ImpQty , @CostOfBidPerc CostToBidPercentage , @BudgetDifference BudgetDifference$ ; IF @Detailed = 1 BEGIN SELECT DISTINCT ReferralURL , RenderingID FROM marketing.Impressions WHERE CampaignID = @CampaignID ; END END
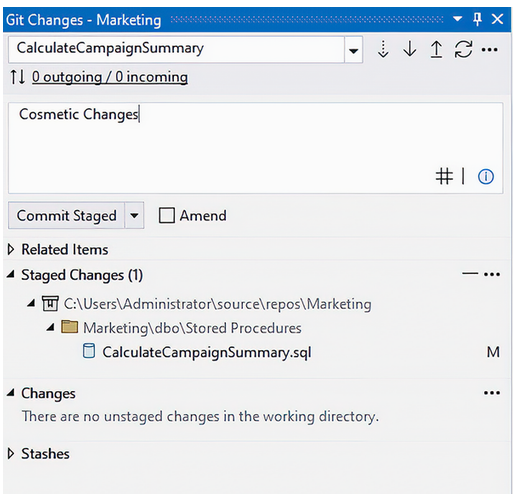
在我们保存文件之后,我们应该再次查看 Git 变化窗口。该窗口已经刷新,以显示我们更改的内容。点击更改旁边的加号将会暂存该更改。反向箭头将会回滚该更改。让我们点击加号图标来暂存更改。
这些更改将被移到已暂存的更改文件夹中,我们现在可以添加提交注释,并使用图 7.8 中显示的“提交已暂存”按钮提交更改。
按下分支下拉菜单旁的向上箭头按钮,将会把更改推送到远程分支。这将在 Git 更改窗口的顶部显示一个黄色横幅消息,其中包含一个用于创建拉取请求的链接。
如果我们已经将代码推送到主干,那么我们只需使用分支下拉菜单切换到主干,然后使用向下箭头按钮将主干拉取到本地仓库。然而,如果我们推送到了远程分支,那么可以点击“创建拉取请求”链接,这会将我们带到 GitHub 网站。在这里,我们可以创建一个请求,让仓库贡献者审核我们的更改并将其合并到主干中。
提示:Git 和 GitHub 本身就值得单独出一本薄书,所以如果你不熟悉这些产品,我强烈建议你深入研究这些主题,因为在本节中我们几乎只是触及了表面。Git 和 GitHub 学习资源页面是一个很好的起点,可以在 https://mng.bz/JN90 找到。
错误#32 不使用 CI/CD 管道部署代码
在我们的场景中,部署问题部分是由于用于将数据库新版本部署到生产环境的方法引起的。MagicChoc 本可以通过打包其应用程序并通过 CI/CD 流水线进行部署来避免这一错误并降低部署风险。
这些流程有多重好处,可以缩短增量版本的上市时间,降低将错误部署到生产环境的风险,并减少部署的复杂性和时间消耗。这是一种非常适合当今敏捷项目方法的流程。
创建 CI/CD 管道是一个涉及多个工具的复杂过程,这些工具通常会由组织进行战略性选择。关于如何配置这些工具的完整说明需要针对所选工具进行具体说明,并且可能需要专门成书来阐述。所选的管道元素同样会根据你企业的需求而有所不同。因此,我不会试图解释详细的配置,而是将讨论相关概念,并鼓励你进行进一步的阅读。
不过,首先让我们来谈谈数据层应用程序(DAC)。DAC 在持续交付环境中很重要,因为它会创建一个包含构成 DAC 的所有工件的包,并为该包分配一个唯一的版本号,这个版本号可以被持续交付流程使用。该包包含所有数据库对象,如表、存储过程和用户,还包括数据库依赖的实例级对象,如登录名。
数据库可以通过多种方式注册为 DAC。例如,我们可以在 SSMS 中通过数据库的上下文菜单注册 DAC,或者,更符合本章概念的方式,我们可以在 Visual Studio 中将一个项目注册为 DAC。
要在 Visual Studio 中注册 DAC,只需发布项目即可。项目构建完成后,将显示部署对话框。在此对话框中,有一个用于注册为数据层应用程序的复选框。如果选中此选项,则会出现一个额外的复选框,允许我们在目标数据库发生偏移时阻止部署。
从构建输出的 dacpac 文件是一个包含数据库对象定义的 XML 文件的压缩文件。它本质上只是一个压缩文件,因此我们可以通过将文件扩展名从 .dacpac 改为 .zip 来探索其内容。
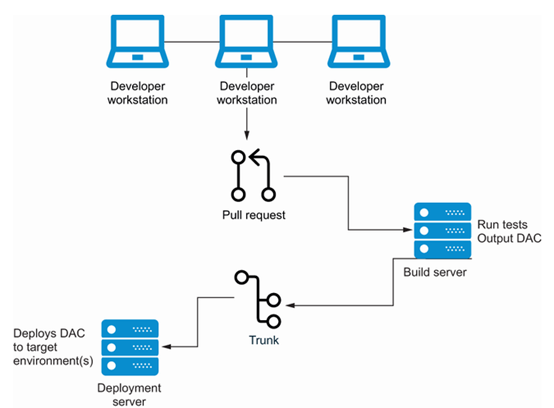
SQL数据库的CI/CD管道中的主要组件是
- 开发人员工作站
- 构建服务
- 部署服务
- 源代码管理
- 环境
开发人员工作站将配备开发工具,例如 Visual Studio、SSDT、Git、Visual Studio Code 等。开发人员在本地创建工件,然后将其提交到源代码控制存储库中的分支,并发起拉取请求。拉取请求通常会触发构建服务。这些构建服务可以通过 GitHub Actions、Azure DevOps 管道或 Jenkins 等工具进行编排。
构建服务将运行我们在前一部分讨论的单元测试,以确保我们的代码没有破坏任何功能。然后,它将创建 DAC 的包。该包将输出为 dacpac 文件。
如果构建成功并且代码已合并到源代码控制的主干中,那么 DAC 可以被部署。部署服务可以包括如 Octopus Deploy、Azure DevOps 或 Redgate Deploy 等工具,并会将 DAC 部署到我们发布堆栈中的最低环境。在一些项目中,这可能是进一步的开发环境;在其他项目中,它可能是集成测试环境,而在少数情况下,它可能是 UAT 或预生产环境。在该环境中的代码获得批准后,可以使用部署服务将 DAC 部署到下一个环境,直到最终到达生产环境。
注意:虽然按定义自动化水平应当很高,但不同的环境会有不同的人为关卡。例如,您可以配置您的环境,使得人在合并到主干之前先审查拉取请求,然后由构建服务触发构建。
图7.9中的图表展示了SQL Server数据库的典型CI/CD流程。
提示 您可能需要进行的进一步阅读取决于贵组织采用的工具。然而,微软有一系列使用 GitHub、GitHub Actions 和 Visual Studio Code 的博客教程,可能会引起您的兴趣。该系列的第一篇可以在 https://mng.bz/M18W 找到。您还可以查阅 Christie Wilson 的 Manning 书籍《Grokking Continuous Delivery》,可在 www.manning.com/books/grokking-continuous-delivery 找到。
我们应该考虑在数据库项目中实施CI/CD流水线。这样做可以帮助我们更敏捷,缩短上市时间,并避免复杂性带来的风险。使用DAC可以通过将所有必需的构件打包在一起并进行版本控制来简化部署。
总结:
- ACID 是一组关于事务的基本规则,规定事务必须是原子性、一致性、隔离性和持久性的。
- XACT_ABORT 用于确定当低严重性错误导致语句失败时,是否终止整个事务。
- 我们应该始终为我们的代码编写错误处理。使用.CATCH 来捕获错误。
- 使用 THROW 和 RAISERROR() 抛出有意义的错误信息。
- 错误严重级别范围从 0 到 24,表示错误的严重性,从信息性消息到关键的硬件或软件故障。
- 如果应用程序有无人值守的进程,应考虑在出现错误时发出警报,以便应用支持团队可以处理这些问题。
- 尽可能使用企业可观察性工具发出警报。否则,请使用数据库邮件和 SQL Server Agent 警报子系统。
- 使用 Visual Studio 调试代码。这可以节省时间并使故障排除更直接。
- Visual Studio 数据库项目具有内置的 SQL 架构比较功能。使用此功能确保在部署之前代码没有发生偏移。
- 使用 SSDT 架构比较功能确保完全理解将要进行的更改以及受影响的功能。
- 始终将 T-SQL 代码保存在源代码控制库中。这将提供版本历史和回滚机制,并有助于简化多个开发人员的项目开发。
- 始终为可编程对象编写单元测试。这样做在前期可能会花费更多时间,但在解决错误破坏现有功能的问题时能节省更多时间。
- 使用现代部署技术。CI/CD 管道可以提供多种好处,包括提高上市时间和降低部署复杂性。


